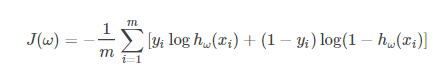随机访问文件中的位置,但是需要保证不取到重复的数值
awk '{ print rand(),$1 }' file.txt|sort -k1 |awk '{ print $2 }' >result.txt
awk '{ print rand(),$1 }' file.txt在第一列加上随机数
awk '{ print rand(),$1 }' file.txt|sort -k1按照第一列随机数排序
awk '{ print rand(),$1 }' file.txt|sort -k1 |awk '{ print $2 }' 按照第一列随机数排序后取得第二列,即原来file.txt文本的第一列。取出需要的个数即可。
两个文件a、b,a和b格式都是每行只有一个字段,需要把两个文件按行合并到一起
awk '{ print NR,$0 }' file1.txt > result1.txt
awk '{ print NR,$0 }' file2.txt > result2.txt
join -1 1 -2 1 -a1 -o 1.2,2.2 aresult1.txt result2.txt > result.txt
用在file1.txt、file2.txt文件中的每一行中增加行号,作为key,然后根据该key来合并连个文件
把file.txt文件按5000一个文件拆分,以lily为前缀
split -l 5000 file.txt lily
将file.txt中重复的数值找出来
sort -n file.txt | uniq -d